D3JS
D3.js adalah library JavaScript yang dipakai untuk memanipulasi dokumen HTML dan menggambar diagram berdasarkan data yang diberikan. Library ini menggunakan HTML, CSS, dan SVG Untuk membuat representasi visual dari kumpulan data yang bisa dilihat diberbagai browser modern.
D3.js juga memiliki fitur untuk membuat diagram yang interaktif dengan animasi-animasi menarik.Di tutorial ini kita akan mengenal konsep dasar penggunaan D3.js. Kita akan pelajari bagaimana menggunakannya dengan me-render sebuah diagram batang, elemen HTML dan SVG, serta menerapkan transformasi dan event ke diagram tersebut.
- Mulai Menggunakan D3
Karena D3.js adalah library JavaScript, untuk memakainya kita
cukup menulis baris berikut di dalam file HTML.
<script src='https://d3js.org/d3.v4.min.js'></script>DOM Selection
Dengan D3.js kita bisa memanipulasi Document Object Model
(DOM), yang artinya kita bsa memilih elemen dan memberikan berbagai jenis
transformasi ke elemen tersebut.
Mari mulai dengan contoh sederhana dimana kita akan memakai
D3 untuk memilih dan mengubah warna dan ukuran font tag heading.
<html><head> <title>Learn D3 in 5 minutes</title></head><body> <h3>Today is a beautiful day!!</h3> <script src='https://d3js.org/d3.v4.min.js'></script> <script> d3.select('h3').style('color', 'darkblue'); d3.select('h3').style('font-size', '24px');</script></body></html>
Disini kita hanya menautkan mehod
select() di
objek d3 yang memilih
elemen tertentu, dan diikuti dengan method style().
Di method style(), parameter pertama
menentukan apa yang ingin diubah dan parameter kedua memberikan nilai yang
baru. Berikut hasilnya: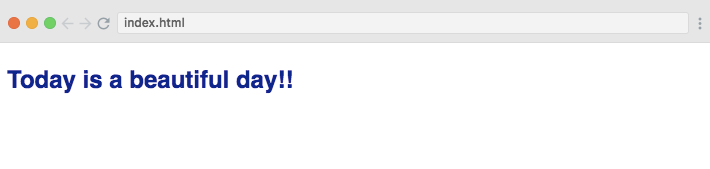
- Data Binding
Konsep berikutnya yang perlu dipelajari adalah data binding karena konsep
ini sangat penting di D3. Dengan menggunakannya, kita bisa mengisi atau
memanipulasi elemen DOM secara realtime.
di HTML kita, tambahkan sebuah tag
<ul>:<ul> </ul>
Kita ingin mengisi unordered list tersebut
dengan sebuah objek data. Berikut kode JavaScript-nya:
<script> var fruits = ['apple', 'mango', 'banana', 'orange']; d3.select('ul') .selectAll('li') .data(fruits) .enter() .append('li') .text(function(d) { return d; });</script>
Pada kode JavaScript di atas, D3 membaca elemen
<ul> dan
seluruh elemen <li> di
dalamnya menggunakan select() dan selectAll().
Agaknya aneh kita membaca elemen li yang
belum kita tamahkan disana, tapi begitulah cara kerja D3.
Kita lalu mengirimkan data dengan method
data(),
dan memanggil enter() yang akan
mengulangi (melakukan looping atau
perulangan) method-method di bawahnya (append dan text)
sampai isi arrray fruits habis di baca
satu persatu.
Dengan kata lain, perintah tersebut, menambahkan sebuah
<li> untuk
setiap item di dalam array. Untuk setiap tag li,
ia juga menambahkan teks didalamnya menggunakan mehod text().
Parameter d didalam text() adalah
fungsi callback yang mengarah
ke elemen di dalam array saat looping terjadi (apple,
mango, dst satu persatu).
Berikut hasilnya:
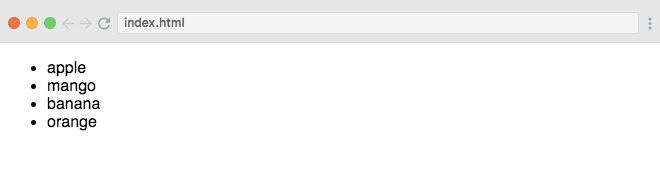
- Membuat Elemen SVG
Scalable Vector Graphics (SVG) adalah sebuah cara untuk me-render elemen
grafis dan gambar ke dalam DOM. Karena SVG berbasis vector, maka ia ringan dan scalable (bisa diperbesar/perkecil
tanpa mempengaruhi kualitas). D3 menggunakan SVG untuk menciptakan
gambar-gambarnya, sehingga SVG menjadi pondasi utama library ini.
Pada contoh di bawah, sebuah kotak digambar menggunakan D3 di
sebuah kontainer SVG.
//Select SVG elementvar svg = d3.select('svg');//Create rectangle element inside SVGsvg.append('rect') .attr('x', 50) .attr('y', 50) .attr('width', 200) .attr('height', 100) .attr('fill', 'green');
D3 akan me-render elemen kotak di DOM. Ia pertama memeilih elemen SVG dan
menggambar kotaknya di dalam elemen tersebut. Ia juga mengatur koordinat x dan
y juga lebar, tinggi, dan warna isinya di method
attr().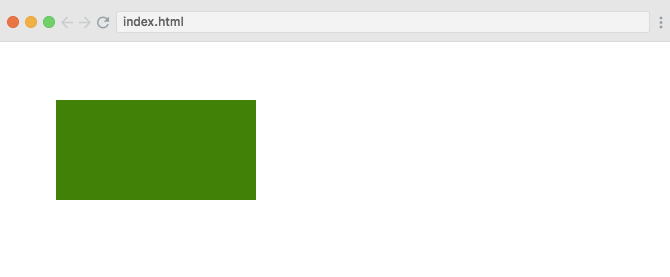
- Membuat Diagram Batang
D3 memungkinkan kita untuk membuat berbagai jenis diagram
agar bisa merepresentasikan data dengan lebih efisien. Pada contoh di bawah,
kita membuat diagram batang sederhana dengan D3.
Mari mulai dengan membuat tag SVG di HTML.
<svg width='200' height='500'></svg>
Lalu, kita tulis kode JavaScript yang kita butuhkan untuk merender diagram
tersebut di tag
<svg>:var data = [80, 120, 60, 150, 200];var barHeight = 20;var bar = d3.select('svg') .selectAll('rect') .data(data) .enter() .append('rect') .attr('width', function(d) { return d; }) .attr('height', barHeight - 1) .attr('transform', function(d, i) { return "translate(0," + i * barHeight + ")"; });
Pada kode di atas, kita memiliki sebuah array yang berisi
angka-angka untuk ditampilkan di diagram batang kita tadi. Setiap item di dalam
array akan mengisi satu batang.
Setelah memilih elemen svg dan rect, kita mengirim data dengan method
data() dan
memanggil enter() untuk
melakukan looping kode-kode di bawahnya sampai isi array habis di baca.
Untuk setiap item, kita menggambar sebuah kotak dan mengatur lebarnya
sesuai dengan nilai yang dimiliki. Kita lalu mengatur tinggi setiap kotak dan
untuk menghindari overlapping, kita memberikan padding dengan mengurangi
barHeight sebesar
1.
Kita lalu memberikan sebuah transformasi agar kotak-kotak tersebut berada
kotak sebelumnya. Fungsi
transform() menerima
fungsi callback yang mengambil data dan indeks data tersebut sebagai parameter.
Kita memodifikasi nilai y kotak dengan mengalikan index dengan tinggi kotak.
Berikut hasilnya:
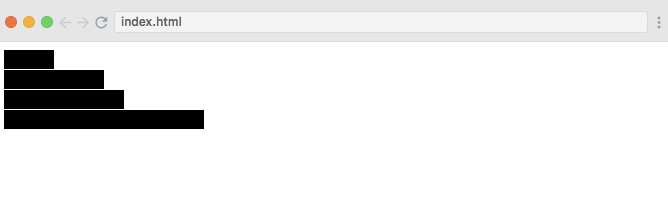
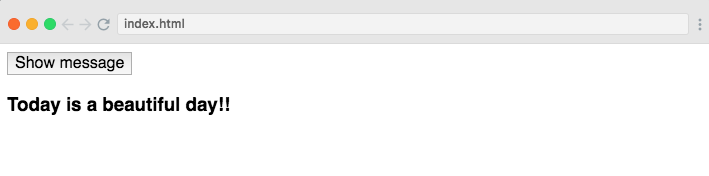
- Event Handling
Terakhir, mari kita lihat bagaimana event
handling di D3. Pada contoh di bawah kita menghubungkan event klik
dengan sebuah button lalu menambahkan sebuah tag heading ke dalam tag body di
event handler-nya.
d3.select('#btn') .on('click', function () { d3.select('body') .append('h3') .text('Today is a beautiful day!!'); });
Jadi, ketika kita mengklik buttont ersebut, akan muncul text
di bawahnya:
Kesimpulan
D3.js adalah library JavaScript yang powerful, namun masih
mudah untuk dipakai membuat diagram dengan HTML, CSS, dan SVG.
REFERENSI :



